What is NLP contract analysis?
Natural‑language processing (NLP) reads contracts like a patient first‑pass analyst: it identifies clause types, extracts key details, and produces short briefs you can act on. Under the hood, a contract‑tuned pipeline cleans and segments text, runs clause classification and legal NER (parties, dates, amounts, jurisdictions), compares language to your playbook using similarity search, and then summarizes positions with clear references back to the source lines.
The point isn’t to replace judgment. It’s to remove scavenger hunts and make the obvious… obvious. Over time you’ll see fewer surprise renewals, faster approvals, and far more consistent negotiations.
Clause classification that maps to your playbook
Start with a practical taxonomy (30–60 clause types for commercial agreements). Distinguish close neighbors—e.g., termination for convenience vs. for cause—so the output actually drives decisions. Good training data pairs examples with counter‑examples and edge cases, so the model learns borders, not just easy wins. Two phrases to naturally include here: nlp contract clause classification and clause taxonomy for contracts.
Entity recognition: parties, dates, money, and the tricky bits
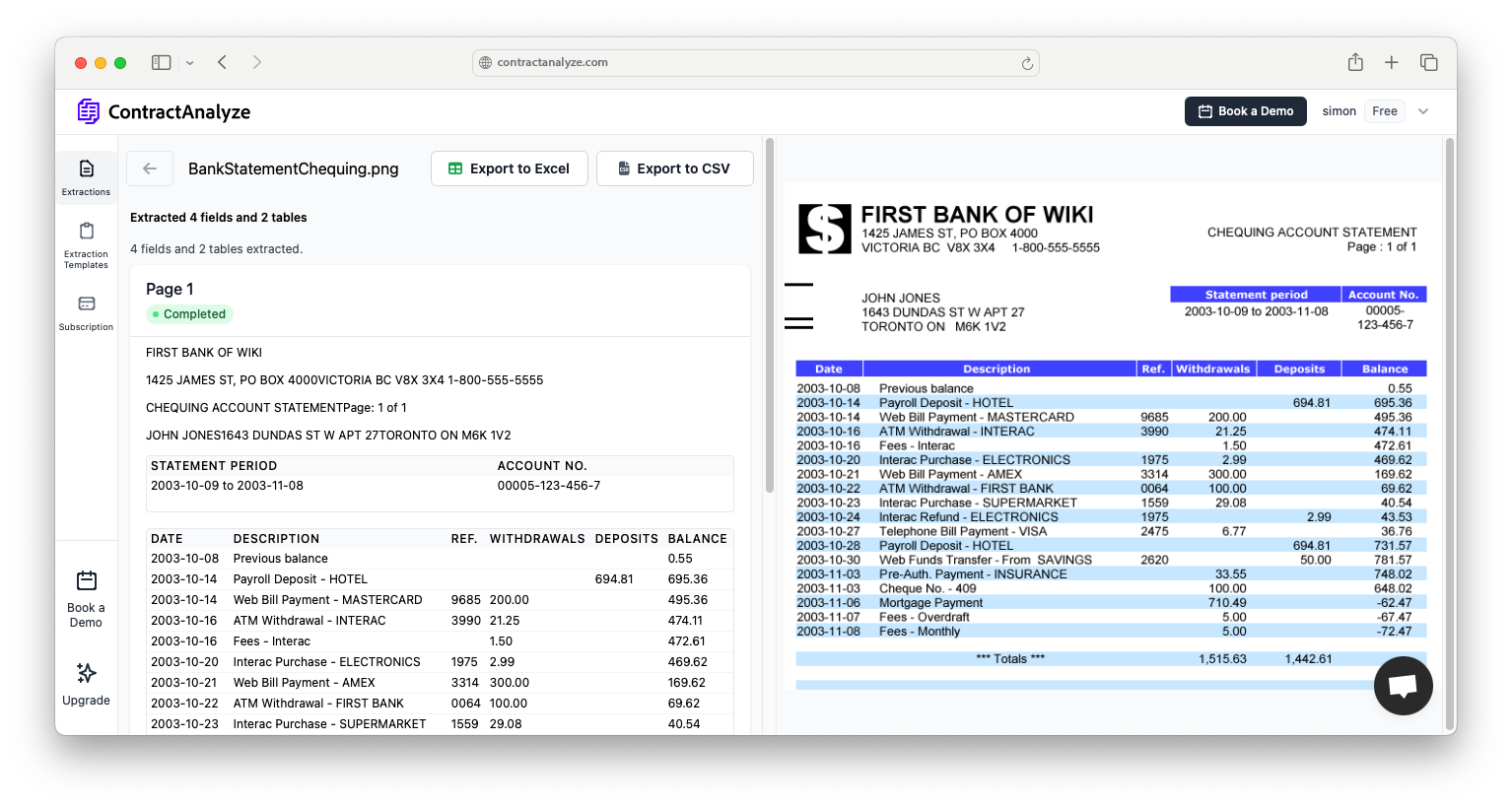
Contracts encode details in fussy ways—“twelve (12) months,” cross‑references, schedules. A legal NER model should pull parties and roles, notice windows, caps, SLAs, governing law, and more. Rules on top can compute acceptability (e.g., notice ≥ 60 days). Tie each entity to its sentence so reviewers can check with one click. Keywords to weave: legal entity recognition contracts, extraction of parties dates amounts law.
Summaries lawyers actually forward
Keep briefs short, neutral, and traceable. One sentence on what the clause does, one on policy fit, one “what to do next,” plus a link to the exact lines. That format becomes the cover note to sales or procurement and cuts back‑and‑forth. Phrase fit: ai contract summarization for lawyers.
Similarity search over your clause library
Embeddings let you find “meaning‑neighbors,” not just keyword matches. Compare each clause to your preferred language, show a diff, and suggest the closest acceptable variant. This is how playbooks become daily reality rather than PDFs on a drive. Add: similarity search for clause libraries.
Risk scoring with reasons (not drama)
Score = likelihood × impact, with a one‑line rationale and a link back to the sentence. Keep the list of automated checks short and useful—renewal window, cap value, carve‑outs, governing law, assignment consent, SLA credits. Measure dismissals and retire noisy checks. Terms: contract risk scoring model legal.
Human‑in‑the‑loop and measurable quality
Publish precision and recall per clause and per entity. Add a simple “confirm / edit / dismiss” control so daily use creates tomorrow’s training data. That steady feedback loop is how accuracy improves without giant retrains. Natural terms: nlp quality evaluation precision recall and human in the loop contract analysis.
Security, privacy, and retention that passes audits
Standard enterprise controls apply: encryption in transit and at rest, short‑lived processing, role‑based access with audit logs, regional residency, and retention controls (including zero‑retention modes for sensitive matters). Document how PII is minimized or redacted. Keyword fit: contract data privacy retention policies.
Integrations that move work: CLM, ticketing, BI
Push structured fields and exceptions to CLM (metadata and approvals), ticketing (owners and due dates), and BI/warehouse (dashboards). Even a tiny “exceptions over time” chart helps leaders see progress. Phrases: contract obligations tracking with ai, enterprise contract analytics dashboards.
A 30‑60‑90 rollout plan
0–30 days: Pick two doc types (NDA, MSA). Lock taxonomy and import playbook. Label 300–500 examples. Pilot on 100 past contracts; measure precision/recall for five must‑catch checks.
31–60: Tune classification/NER, add brief templates and exception reasons, connect CLM/ticketing, run a weekly 30‑minute labeling session.
61–90: Go live for pilot docs, add dashboards, expand to one more doc type (DPA/SOW), publish accuracy and a feedback channel.
Common wins and how to measure them
Teams usually report quicker first‑pass reviews on NDAs and standard MSAs, fewer surprise renewals thanks to notice tracking, and cleaner negotiations because carve‑outs/caps are obvious up front. Track before/after on missed renewals, time‑to‑close, and exception rates for 3–5 key clauses. Phrase: playbook alignment contract review.
Quick FAQs
Do we need data scientists? Not to operate it—legal ops can run the feedback loop; your vendor manages modeling. How much data? Hundreds of well‑labeled examples per clause type get you moving; thousands tighten accuracy. Scans? Supported—measure separately.