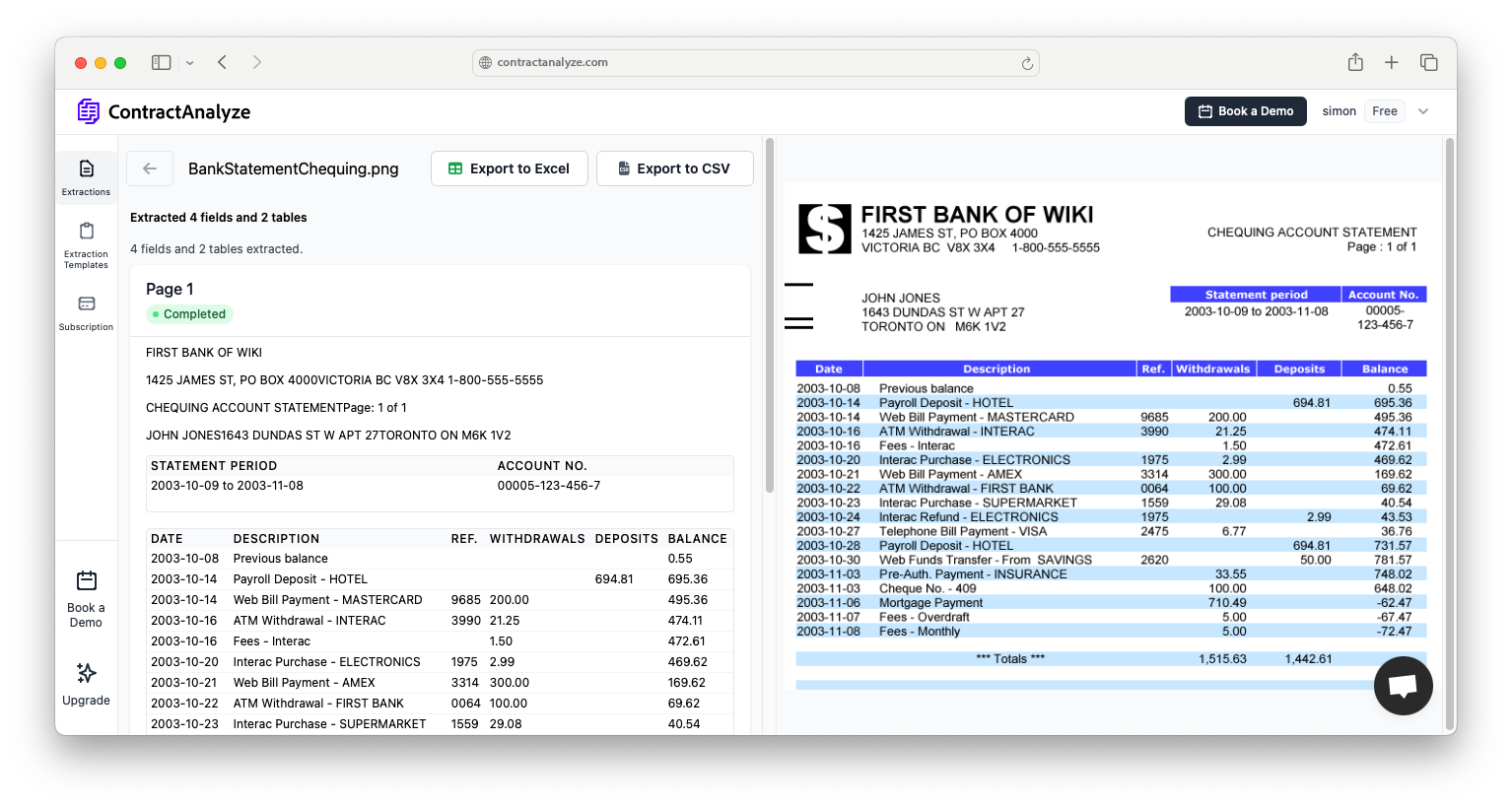
What “machine learning contract analysis” actually means
Machine learning (ML) turns piles of contracts into structured data and helpful notes. It excels at repeatable work: clause classification, legal entity recognition (parties, dates, amounts), and short, traceable briefs. A practical pipeline cleans text, segments sections, classifies clauses, extracts entities, runs similarity search against your playbook, then summarizes positions and flags exceptions with reasons.
Teams use this to cut first‑pass review time, reduce surprise renewals, and standardize negotiations. It doesn’t replace judgment—ML simply handles the hunt-and-verify steps so humans focus on decisions.
Core components: classification, entity recognition, and summarization
Three building blocks carry most of the load. Clause classification labels text as termination, limitation of liability, governing law, and so on—granularity enables better routing and checks. Legal NER extracts parties, affiliates, dates, notice windows, caps, SLAs, and jurisdictions (including quirky formatting like “twelve (12) months”). Finally, a brief summarizes the position and links back to the exact lines. Similarity search over your clause library spots wording that “means the same” or drifts from policy.
Building a clause taxonomy that your model can learn
Start with a realistic taxonomy—30–60 clause types for MSAs/SOWs; fewer for NDAs/DPAs. Write labeling rules with examples and tie‑breakers and measure inter‑rater agreement. Include negative and edge cases so models learn the boundaries, not just the obvious center.
Training data: where it comes from and how to keep it clean
Mix your own contracts with curated public samples. Clean OCR, strip artifacts, and split data by document (not sentences) for honest generalization. Keep a weekly QA loop: spot‑check samples, label model mistakes, and fold them back in. Track precision/recall by clause and entity so regressions are obvious.
Quality you can trust: precision, recall, and human‑in‑the‑loop
Publish precision and recall tables—especially for “spicy” clauses like liability. Add simple “confirm / edit / dismiss” controls to turn daily reviews into new training data. Human‑in‑the‑loop keeps accuracy improving without giant retrains.
Risk scoring that’s useful (and not dramatic)
Sort work by likelihood × impact with one‑sentence rationales and links to the source lines. Prioritize 5–7 checks people actually act on (renewal window, cap value, carve‑outs, governing law, assignment consent, SLA credits, data processing limits). Measure what’s caught vs. dismissed and retire noisy checks.
Playbook alignment and similarity search
Encode policy as rules and run them on every contract. Pair with embeddings‑based similarity to your clause library so reviewers see “what this is closest to,” the diff, and a recommendation. This is where consistency compounds across the portfolio.
Summaries and briefs people actually forward
Keep briefs short, neutral, and traceable. One line on what the clause does, one line on policy fit, one suggested next step, and a link to the lines used. These become the cover notes to sales/procurement and cut back-and-forth.
Integrations: CLM, ticketing, BI
Push structured outputs to the tools that move work: update CLM metadata, create tickets for owners/dates, and store fields/exceptions in your warehouse for dashboards. A tiny “exceptions over time” chart makes value obvious to leaders.
Security, privacy, and retention
Use encryption in transit and at rest, short‑lived processing, role‑based access with audit logs, regional data residency, and retention controls (including zero‑retention). Document PII handling/redaction paths for compliance reviews.
A 30‑60‑90 plan teams actually finish
0–30 days: Pick two doc types (NDA, MSA). Lock taxonomy, import playbook, label 300–500 examples, pilot 100 past contracts; measure precision/recall for five checks. 31–60: Tune NER/classification, add summaries and exception reasons, connect CLM/ticketing, run weekly 30‑minute labeling. 61–90: Go live, add dashboards, expand to one more doc type (DPA/SOW), publish accuracy and a feedback channel.